算法简介 Algorithm Introduction
- 要点介绍
AutoCoder是一个用于检测分布式系统的节点故障类型的项目,它提供了完整的故障类型检测和诊断流程, 并提供相应的数据预处理、模型训练、评估、自训练、数据分析脚本。
AutoCoder提供了极简使用与深度自定义两种模式,本项目的核心功能都可以仅输入路径等参数以默认值实现, 使用门槛低,与此同时也在训练、自训练等功能上提供了丰富的自定义参数,以便于专业人士按需进行测试和调整。
AutoCoder主要包括模型训练,预测,数据分析,自训练等功能。
- 训练
使用supervised.automl.AutoML的fit方法进行训练,特点如下:
1.模式预设: AutoML提供三种常用预设参数,分别适用于运行测试、生产环境以及极限性能, 运算成本、训练时间、模型大小依次递增,用户可以自行选择合适的预设。通过mode参数设置。
2.支持多种算法:
AutoML可以使用多达九种算法,包括
Baseline, Linear, Random Forest, Extra Trees, LightGBM, Xgboost, CatBoost, Neural Networks, Nearest Neighbors,
支持用户按需自行选择。通过algorithms参数设置。
3.支持基线计算:
AutoML可以使用Baseline计算数据的基线,以便判断是否需要使用机器学习的方法。
Baseline是一种简单的模型或启发式方法,根据先验类分布(分类任务)或简单的平均值(回归任务)进行计算,
用于判断任务的复杂程度。
4.自动完成数据预处理: AutoML会自动进行基本的数据预处理,如缺失值插补、标准化、格式编码等, 也会自动进行目标值预处理,例如将分类目标转换为数字,不需要用户额外操作。
5.支持模型堆叠:
AutoML可以根据贪婪算法计算Ensemble,可以堆叠模型以构建二级集成,
启用后可以降低过拟合风险、提高预测准确率。通过stack_models参数设置。
6.支持自动进行特征工程:
AutoML可以自动进行特征选择和特征组合,
不需要额外进行特征工程。通过composite_features和features_selection参数设置。
7.支持自动进行超参数调整:
AutoML可以自动进行超参数调整,通过hill_climbing_steps和top_models_to_improve参数设置。
8.模型解释性:
对于每种算法,AutoML都会基于排列计算特征重要性,
并计算SHAP解释、特征重要性、依赖图和决策图。通过explainlevel参数设置。
9.自动创建训练报告:
AutoML可以自动创建Markdown格式报告,包括详细的训练记录、性能指标以及热度图。
建议
-
极简使用:只需要传入数据集路径即可进行训练
-
自定义使用:可传入
AutoML(**kwargs),参见API文档AutoML class
Simple training method, only need to pass in the data set path for training
Source code in function\train.py
6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | |
- 预测
使用supervised.automl.AutoML的predict方法进行预测,特点如下:
1.输出方式全面:对于分类任务,支持输出分类标签或者每种标签的概率,
分别使用supervised.automl.predict()和supervised.automl.predict_proba()
进行预测,或者使用supervised.automl.predict_all()预测
2.自动判断任务:在类别过多时自动判断为回归任务,使用supervised.automl.predict_all()进行预测
- 自训练
提供了自训练方法,可以使用semisupervised.autost.AutoST的fit方法进行自训练。
适用场景
AutoST是一种半监督学习方法,在以下场景下可能有比监督学习更好的效果:
-
数据标注成本高:在实际应用中,获取未标记的数据比获取标记的数据要容易得多,例如对于需要专业的人力来进行数据标注的场景,此时自训练可以利用大量的未标记数据来提高模型的性能。
-
标记数据稀缺:如果可用的标记数据可能非常稀缺,而未标记数据则相对丰富,可能只有极少数的标记样本可用,自训练可以通过利用未标记数据来缓解标记数据稀缺的问题。
-
数据分布发生变化:如果训练数据和测试数据的分布有所不同(即领域偏移),那么训练在训练数据上的模型可能在测试数据上的性能不佳。自训练可以通过在未标记的测试数据上进行额外的训练,来缓解领域偏移的问题。
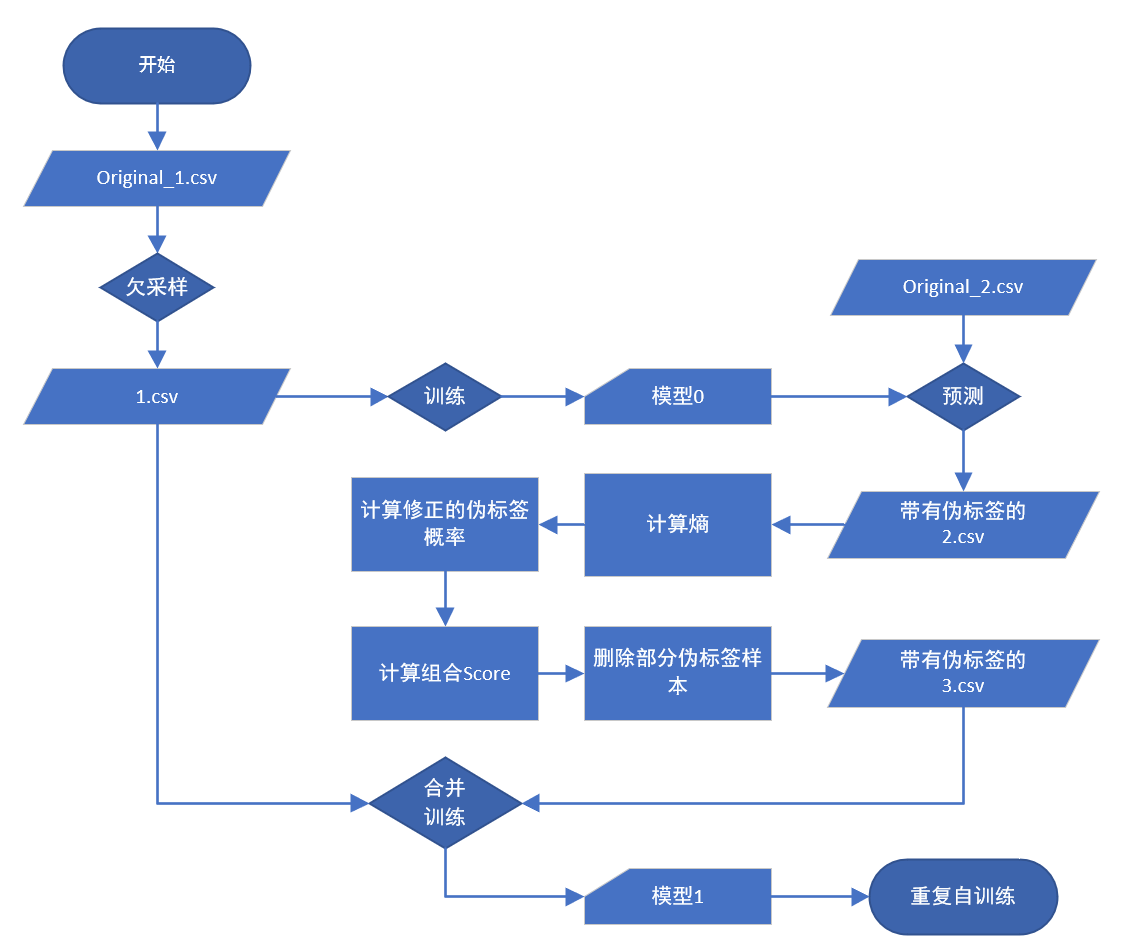
实现逻辑
-
训练初始模型:首先,使用有标签的训练数据集训练一个初始模型。这可以使用任何AutoML提供的算法完成;
-
预测未标记数据:然后,使用训练好的模型对未标记的数据进行预测,生成这些数据的标签,称之为伪标签。这些伪标签在初次生成时可能有一些不准确,但随着模型的迭代训练,它们应该会逐渐改善。
-
合并数据:按照一定规则选择部分伪标签样本,将其与原始的有标签数据合并,形成一个新的训练集。
-
再次训练模型:使用合并后的新训练集再次训练模型。这次训练会包含原始的有标签数据,以及模型预测出的标签的未标签数据。
-
迭代过程:重复步骤2-4,直到模型的性能达到某个预定的标准,或者预测的标签不再发生显著变化。
伪标签选择方式:
伪标签选择方式有多种,本文选择UPS方法,具体思想如下:
UPS 框架由两个主要部分组成:预测概率和预测不确定性。预测概率可以从模型的输出直接得到,而预测不确定性需要使用特定的方法进行计算。 预测不确定性的计算方法有很多种,例如可以使用模型的预测方差、熵或者基于贝叶斯的方法。本项目使用了基于熵的方法来计算预测的不确定性
然后,UPS 将预测概率和预测不确定性结合起来,形成一个新的评价指标,用于选择伪标签样本。具体的选择策略可以是预测概率和预测不确定性的加权和、乘积,或者其他的组合方式,得到的P_max是模型预测的最大概率,λ是一个超参数,用于控制预测概率和预测不确定性的权重。
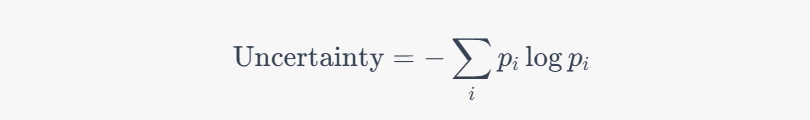
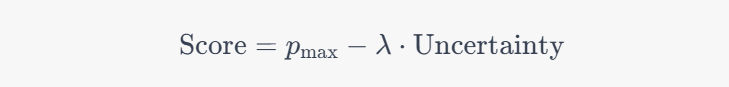
具体流程
如图所示:
- 数据分析
1.生成单个数据集分析报告:
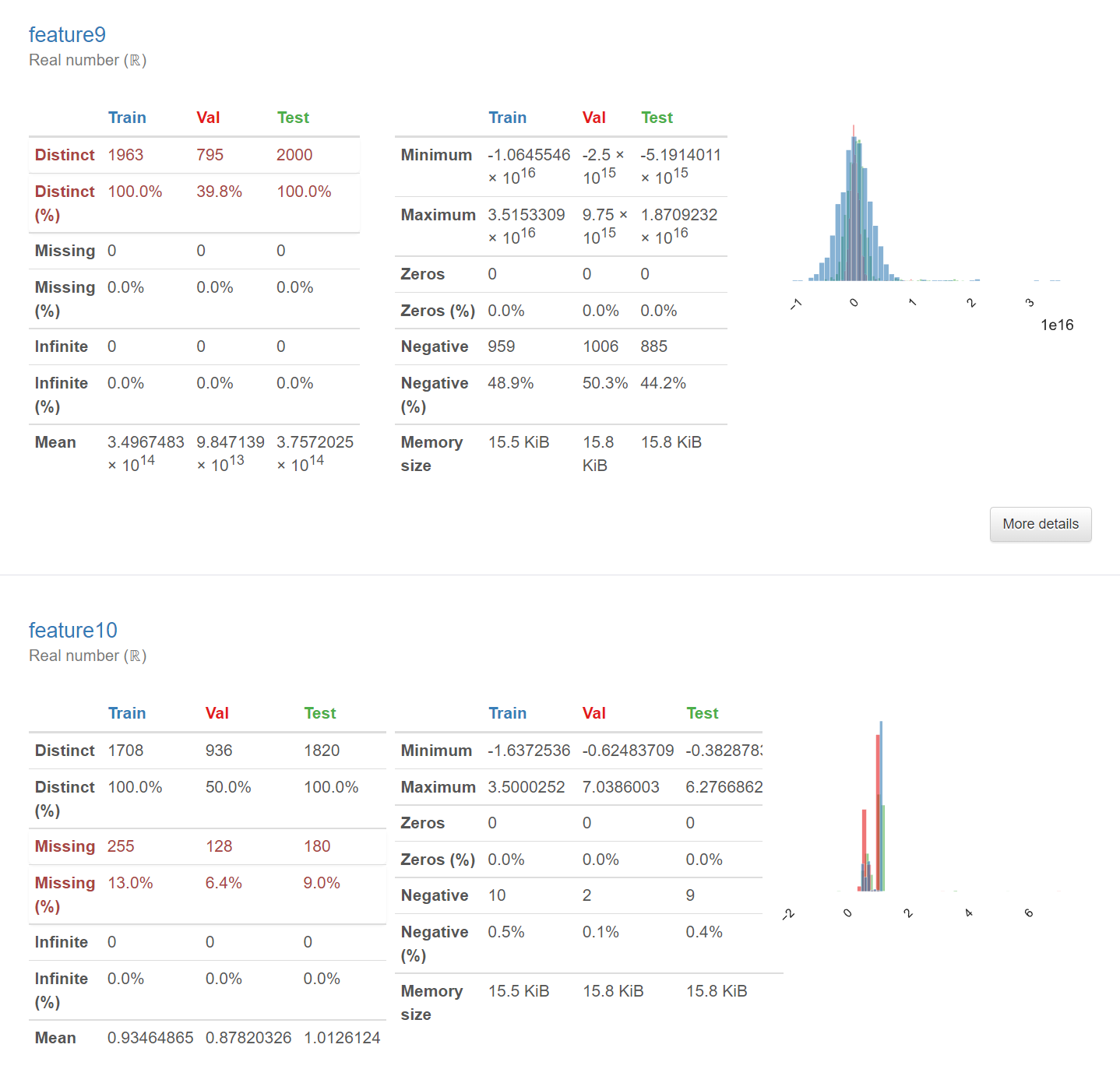
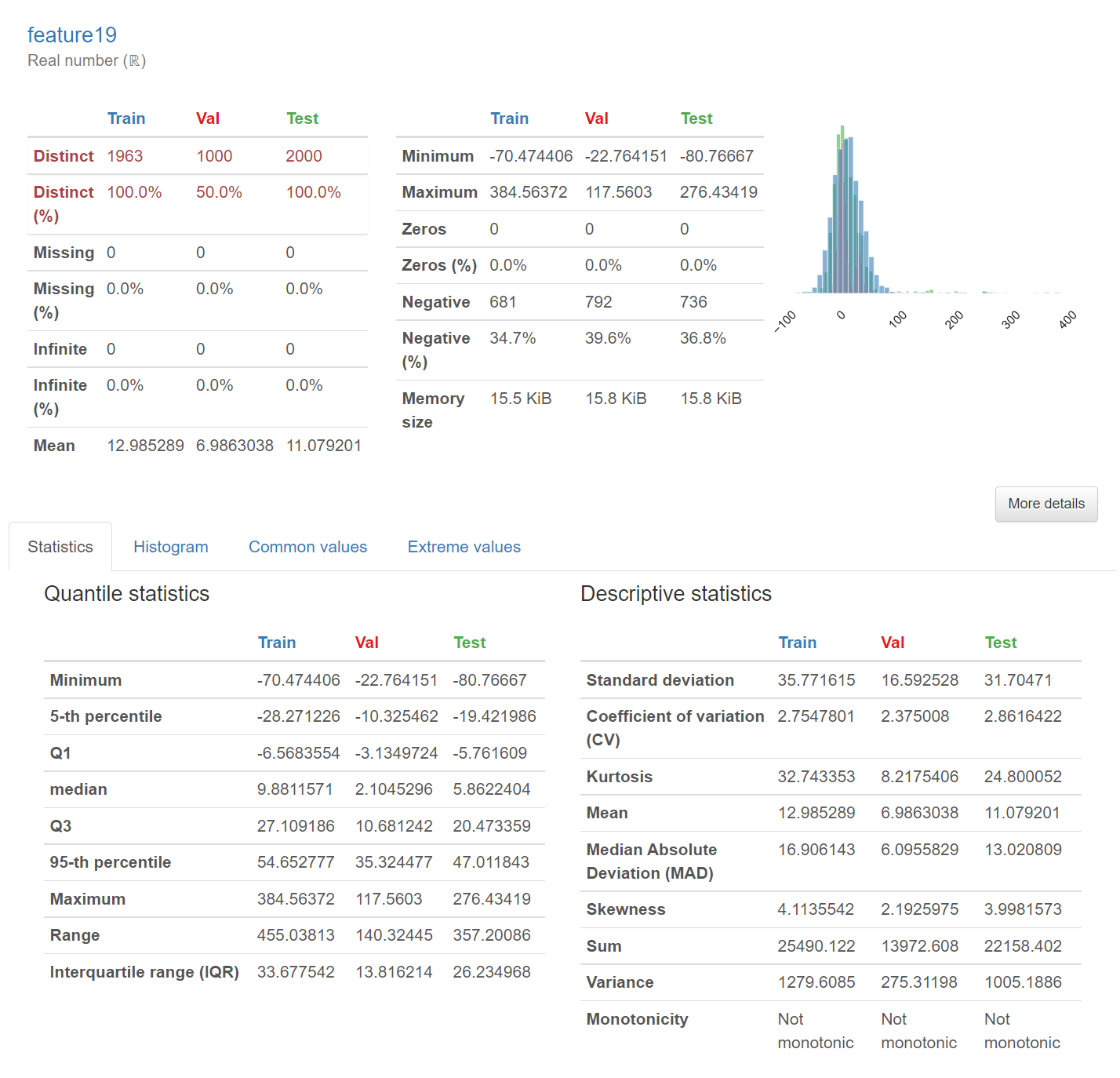
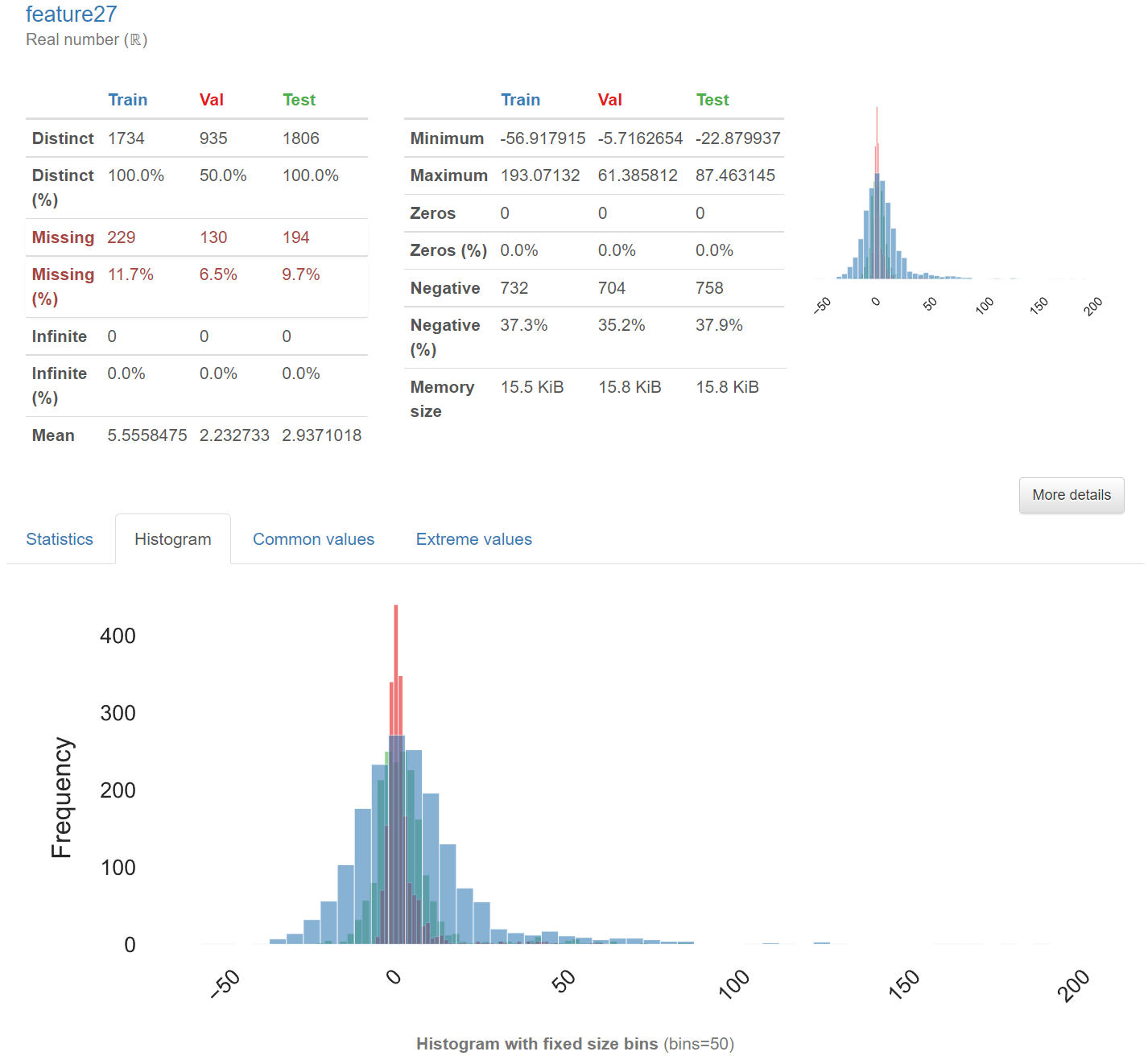
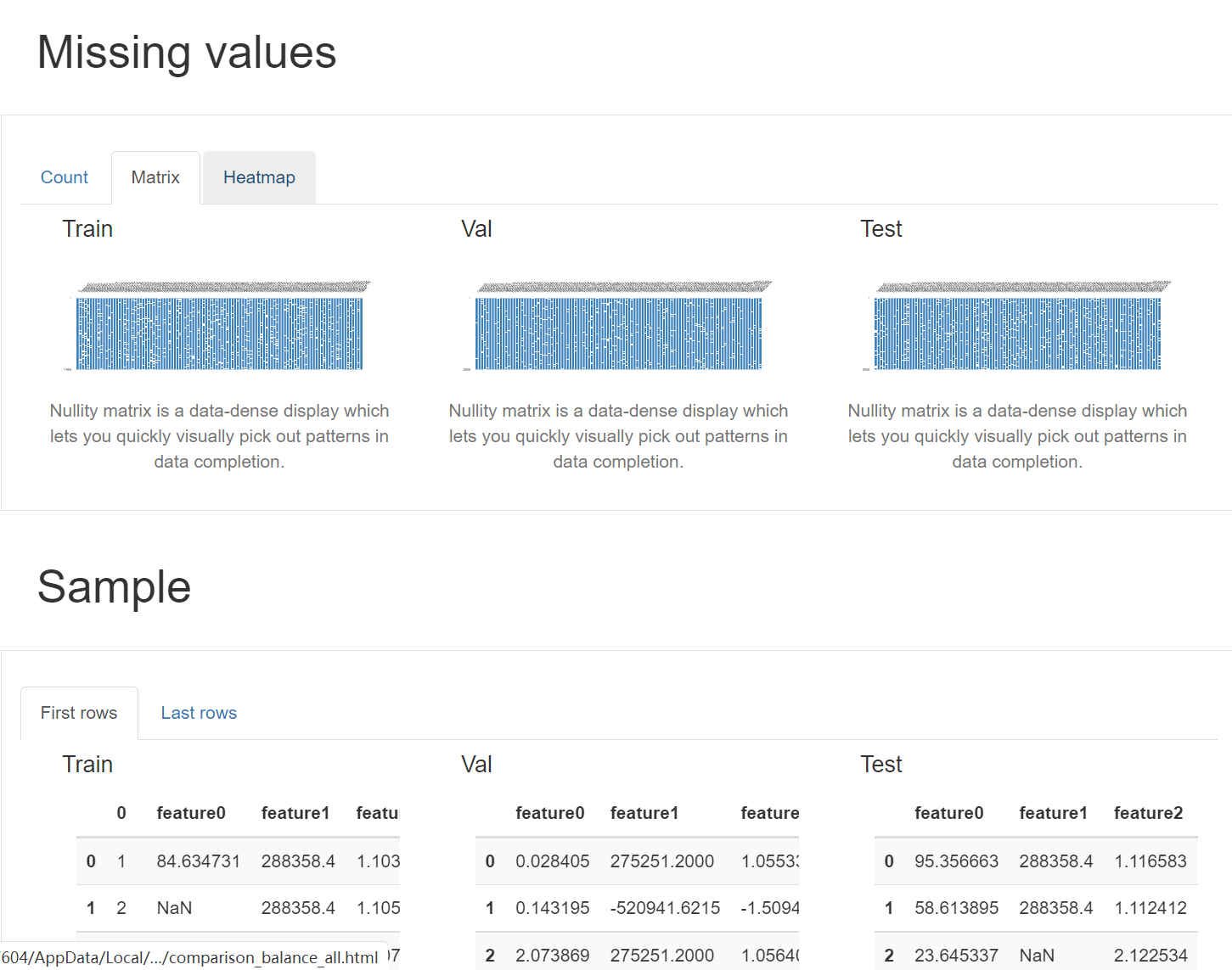
支持对单个数据集进行计算与数据分析,您只需要提供数据集,即可生成HTML报告,报告包括了:
-
数据概览:提供了数据的概览,包括样本数,列数,缺失值的数量,重复值的数量等等。
-
变量的概览:对每个变量进行了详细的分析,包括统计特性(平均值,中位数,方差等),直方图(对于数值型变量),条形图(对于分类变量),缺失值的数量等等。
-
相关性分析:计算了变量之间的相关性,并以热力图的形式进行展示。默认情况下,会计算
Pearson,Spearman,Kendall和Phik这四种相关性。 -
缺失值的分析:提供了缺失值的分析,可以很方便地看到每个变量缺失值的数量,以及缺失值之间的关系。
-
样本的分布:会分析样本的分布,包括数值型变量的分布,分类变量的频数等等。

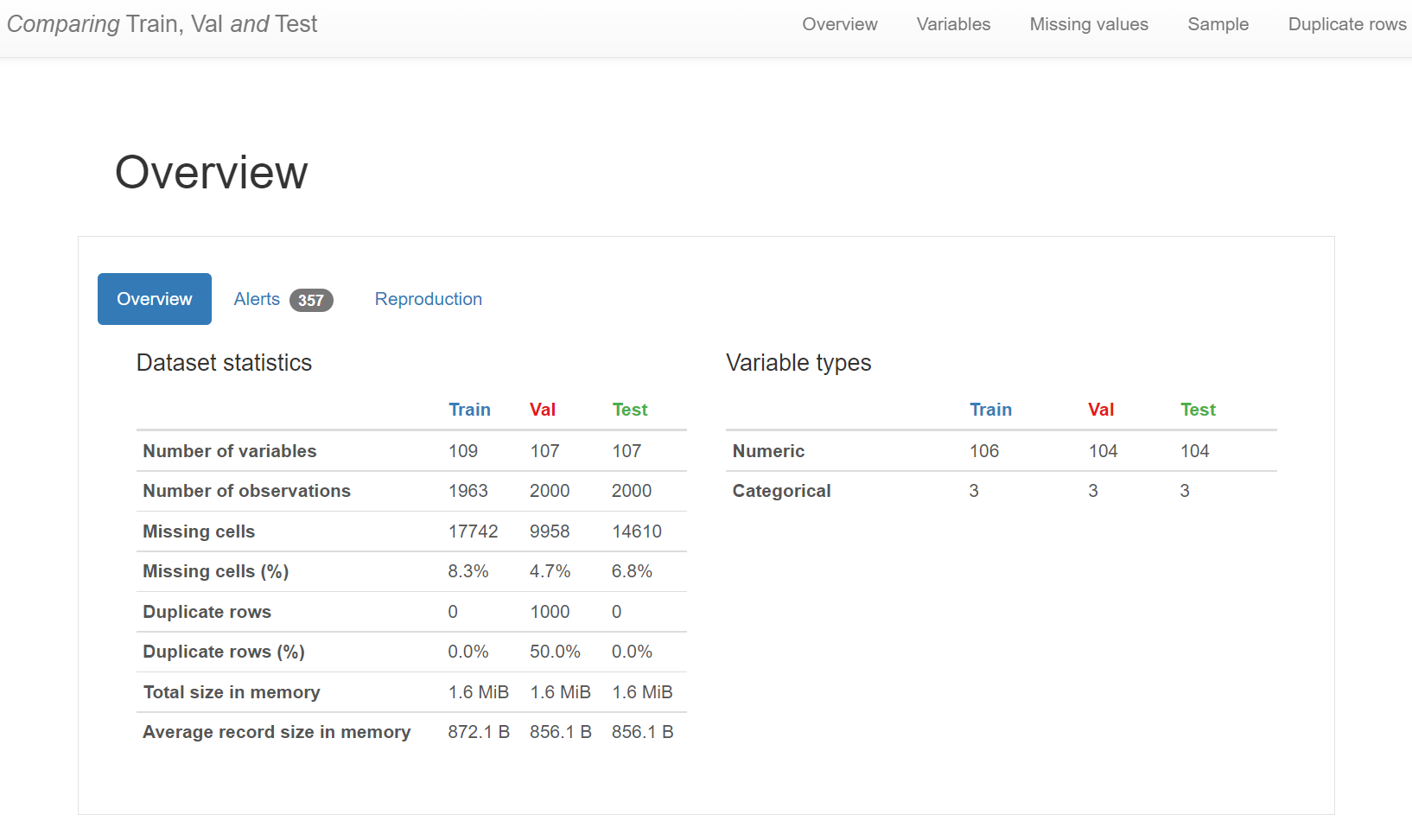
2.生成多个数据集对比报告:
支持对多个数据集进行计算与数据分析,并生成对比报告,您只需要提供数据集,即可生成多个数据集的HTML对比报告。
上述步骤的详细说明均可在API栏目查看